前端工程化:有效地进行拼写检查
拼写错误导致的问题
在项目开发过程中,即使我们再细心,也难免忙中出错,犯下很多低级的错误。
比如这样:
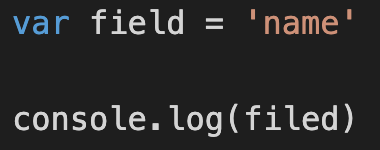
我们错把 field 拼写成 filed,这样打印出来的是 undefined,而不是预期的 name。
ESLint 的基本介绍
但是幸运的是,有一些 Lint 工具会在这方面提供一些帮助。
比如在 TypeScript 中,会有一个错误提示。虽然这个提示提供的消息并不是我们需要的。
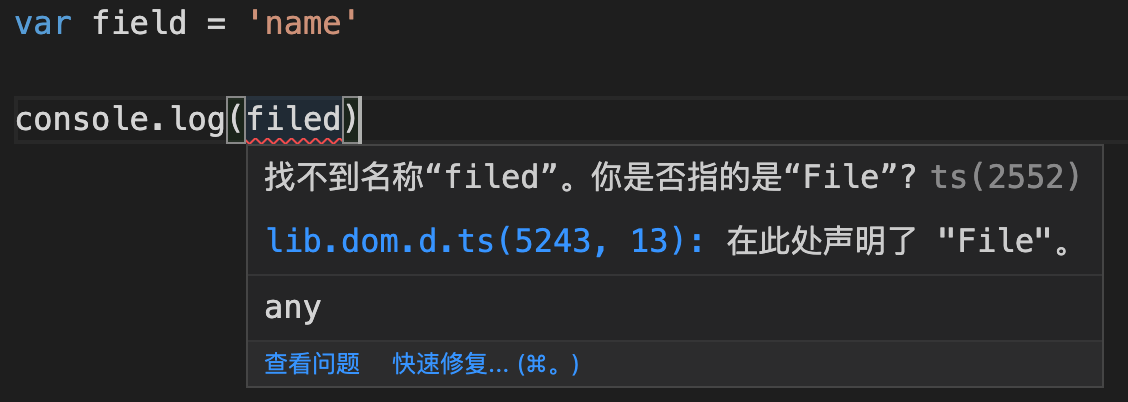
当然我们可以选择一些更专业的 Linter 来完成这项工作。
目前来说,最流行的 JavaScript Linter 是 ESLint。
如果配合 VSCode 这个编辑器使用的话,可以安装 vscode-eslint 这个插件。
然后在项目的根目录下创建 .eslintrc.js 文件,编写一些配置。
/** @type {import('eslint').Linter.Config} */
module.exports = {
env: {
browser: true,
es2021: true,
node: true,
},
rules: {
"no-undef": ["error"],
},
};
env 属性指定项目的运行环境。
rules 是具体的规则。
no-undef 这条规则的意思是不可以使用未定义的变量。
no-undef 属性的值是一个数组,数组的第一个元素是这条规则的级别。
ESLint 中的所有规则都有 3 个等级,off 表示关闭,wran 表示警告和 error 表示错误。
你可以根据自己对代码要求的严格程度自定义规则等级。
当我们配置好了这条规则之后,编辑器的错误提示就会发生变化。
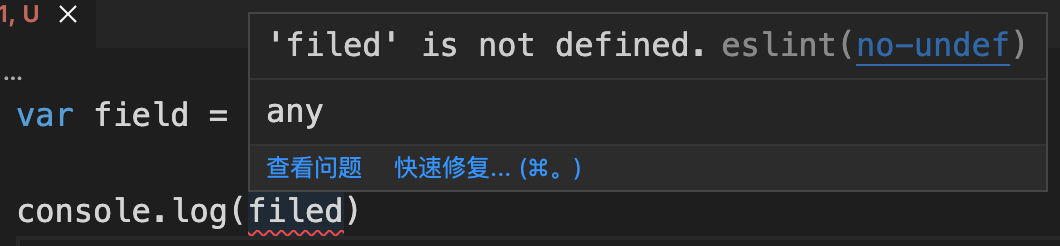
ESlint 会给我们提示 filed 这个变量没有被定义,而被直接使用了。
这样就可以帮助我们发现这个问题,从而更早的解决掉这个问题。
这是一种比较容易发现的问题。
声明变量时的单词拼写错误
另一个更加隐秘晦涩的错误是,我们在定义变量时就把变量的单词拼写错了。
比如下面这样:
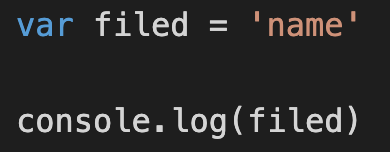
这种问题 ESLint 是没有办法检测到的,而且真正运行起来也不会有什么问题。
最大的问题在于维护。
假设这段代码的维护者换成了别人,他很难一眼看出这段代码究竟在表达什么意思。
filed?是文件的过去式,表达的意思是归档吗?
他压根就不可能会朝 field,也就是字段的含义上去考虑。
这会让接下来的整个逻辑流程阅读起来变得非常费解。
这种问题属于根源性的问题。
人工解决方案
解决办法当然存在,建立业务术语表,然后经过人工代码审查(CodeReview)。
但是,人在真正意义上是不靠谱的。
即使再强大、再细致的人,也会有焦急、疲倦、松懈的时候。所以即使是通过人工代码审查后的代码,也未必不会存在上面提到的这种问题。
机器解决方案
那么能够有一种更好的方式来避免这类问题呢?
比如能否依靠在真正意义上靠谱的机器来协助人类做这件事情?
当然是可以的。
ESLint 有一套插件机制,可以通过插件来扩展 ESLint 原本的功能。
其中有一个比较常用的插件,eslint-plugin-spellcheck。
这个插件的作用是帮助我们检查单词的拼写错误。
安装也非常简单。
npm install eslint-plugin-spellcheck
之后需要更新 ESLint 的配置。
/** @type {import('eslint').Linter.Config} */
module.exports = {
env: {
browser: true,
es2021: true,
node: true,
},
plugins: [
"spellcheck",
],
rules: {
"no-undef": ["error"],
"spellcheck/spell-checker": ['warn']
},
};
这样就可以对代码中单词拼写错误的。
拼写错误与意图表达错误
但是,讲了这么多,像上面提到的反例,spell-checker 仍然是无能为力的。
为什么呢?因为上面提到的反例,表面上看只有一个错误,但无形之中还存在另一个错误。
- 拼写错误,field 拼写成了 filed。
- filed 仍然是个正确的单词。如果将 filed 认为是一个正确的单词,那么第二个错误将是意图表达错误。
机器只能解决拼写错误,但是意图表达错误这类问题明显超越了机器目前的能力边界。
所以我们可以把反例稍微改一下。
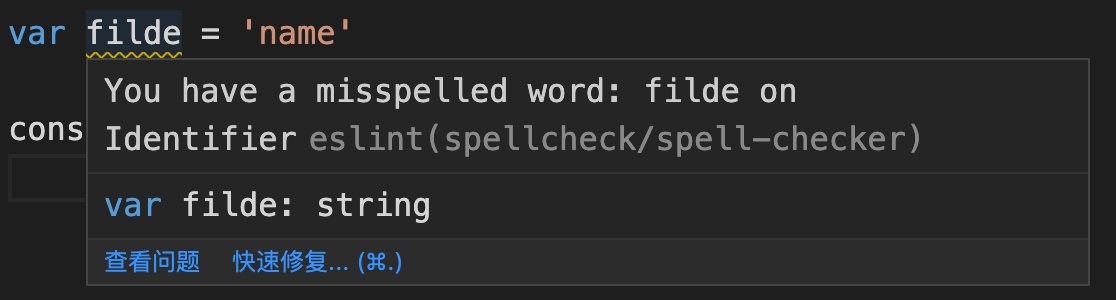
filde 不是一个合法单词,所以就得到 spell-checker 的警告提示。
spell-checker 的实现原理
spell-checker 的实现原理就是罗列出超过 4 万个英文单词进行匹配,如果不在这个范围内的英文单词就认为是拼写错误。
当然我们也可以扩展这个单词列表。
ESLinter 的 rules 中属性值都是一个数组。第一个元素是规则级别,第二个元素就是一个对象,表示这个规则对应的配置项。
spell-checker 的配置项中有一个 skipWords,表示可以跳过一些单词。
跳过特殊单词
比如你在使用 ESModule 的方式来开发应用,其中用到了 Vue 这个库。
我们需要在 .eslintrc.js 中添加一项配置,让 ESLint 的解释器以模块的方式解释代码。
module.exports = {
// ...
parserOptions: {
sourceType: 'module'
}
}
但是 Vue 并不是一个合法的单词。

我们就可以通过配置这个配置项来跳过对 Vue 的检测。
module.exports = {
rules: {
"spellcheck/spell-checker": [
"warn",
{
skipWords: ["Vue"],
},
],
}
这样代码就不会再出现警告了。
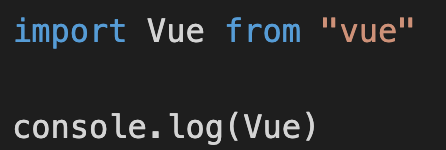
但是到目前为止,问题还是没有完全解决。
因为一些库中提供的 API 仍然不是合法单词。比如 Teleport。

我们可以选择手动添加 Teleport 这个单词到 skipWords 中。
但问题是,Vue 中仍然提供了很多 API 不在合法单词范围内,比如 withCtx:

如果我们碰到哪个单词就朝 skipWords 里面添加哪个单词,在使用的库比较少的时候还可以接受。如果我们的项目中依赖了大量的库,而这些库中又存在了大量的不合法单词 API,这会让我们感到非常的繁琐和痛苦。
另外一个问题就是,Node.js 很多内置模块的 API 同样不是合法单词。比如常用的 fs 和 readdir。
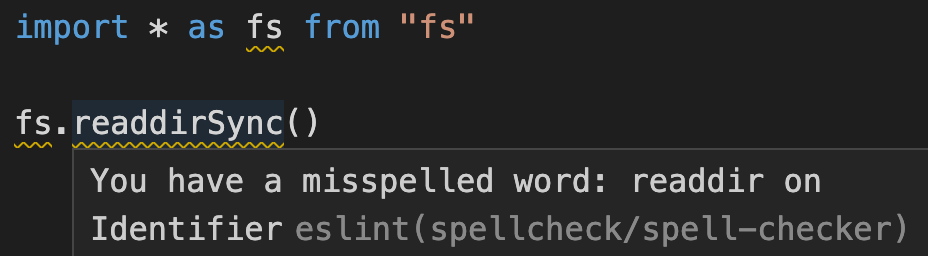
那有没有什么方法可以解决上面的两个问题呢?
答案是有的。
modules-words
modules-words 是一个获取模块 API 单词的库,通过这个库配合 spell-checker 可以很好的帮助我们跳过很多第三方模块或者 Node.js 内置模块的 API 单词检查。
首先安装这个模块。
npm add modules-words --save-dev
之后修改 .eslintrc.js 配置文件。
const { getWords, getGlobalWords } = require("modules-words");
/** @type {import('eslint').Linter.Config} */
module.exports = {
// ...
rules: {
// ...
"spellcheck/spell-checker": [
"warn",
{
skipWords: ["", ...getWords("vue"), ...getGlobalWords()],
},
],
},
};
通过 modules-words 提供的 getWords 和 getGlobalWords 两个函数,成功地将项目中可能使用到的单词过滤出来,让 spell check 能够以更加符合我们预期的方式运行。