用 requests 请求豆瓣
浏览 2910
课文
因为爬虫的本质是模拟用户从网站上抓取数据的一个过程,这使得我们在编写第一行代码前应该先了解下网站的工作原理。
网站的工作原理
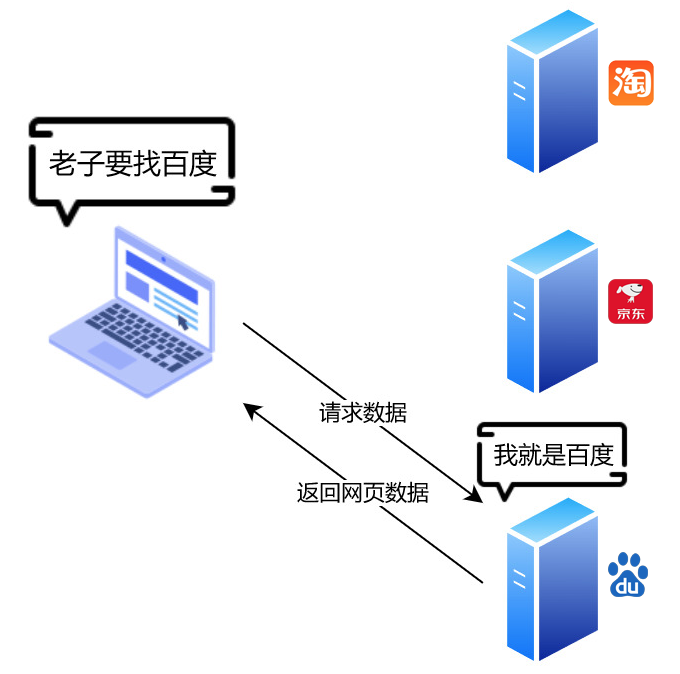
网络请求
在世界各地存在着无数的服务器,他们或许是阿里的服务器,或许是京东的服务器,当然还有我们三眼鸭的服务器,这些服务器上保存着网站相关的数据。
在网络上的服务器都会有一个唯一的 IP 地址, 我们通过 IP 就能找到这台服务器。由于 IP 是一串数字很难记,就衍生出了 DNS 服务来保存域名与 IP 的对应,用有含义的域名来代替了 IP 的使用。
当我们在浏览器输入 https://baidu.com 这个域名的时候,浏览器先去 DNS 服务器找到百度的IP,然后连接上 IP 向百度服务器说明我们正在请求它的网站,于是百度的服务器便会返回网站的数据。浏览器拿到返回的网站数据后会通过一定规则解析成我们看到的网页。
网页组成
返回的网站数据主要由三部分组成 — HTML、CSS 和 JavaScript。
- HTML:组成网页的基本元素与结构
- CSS:包含网页的样式
- JavaScript:可运行的脚本代码
<html>
<head>
<style type="text/css">
.word {
color: red;
}
</style>
<script type="text/javascript">
alert("三眼鸭欢迎你")
</script>
</head>
<body>
<p class="word">一个基本的网页</p>
</body>
</html>
这便是一个基本的网页,HTML 用前后标签的形式来组成一个基本元素,<p class="word">一个基本的网页</p> 是一个基本的文本标签。 css 样式则是放在 <style> 标签中, color: red; 指定了文本的颜色。<script> 标签内是 javascript 的执行代码, alert("三眼鸭欢迎你") 表示在网页打开的时候弹出一个提示框。
了解网页的基本组成,可以帮助我们从网页中提取想要的数据时,有一个清晰的思路。比如我们想提取文章的标题时,就需要根据标题所用的 HTML 标签、 CSS 样式等约束条件将它与其他元素区分开来。而很多数据是通过 JavaScript 来从服务器加载的,了解 JavaScript 能帮助我们更快地找到数据来源。
关于 HTML、CSS、JavaScript 我们需要有一个基本的了解,又不需要过早的深入,有关的知识点我们会在之后学习中逐步接触到。
用 requests 获取网页
之后的操作我们会以谷歌浏览器作为显示。
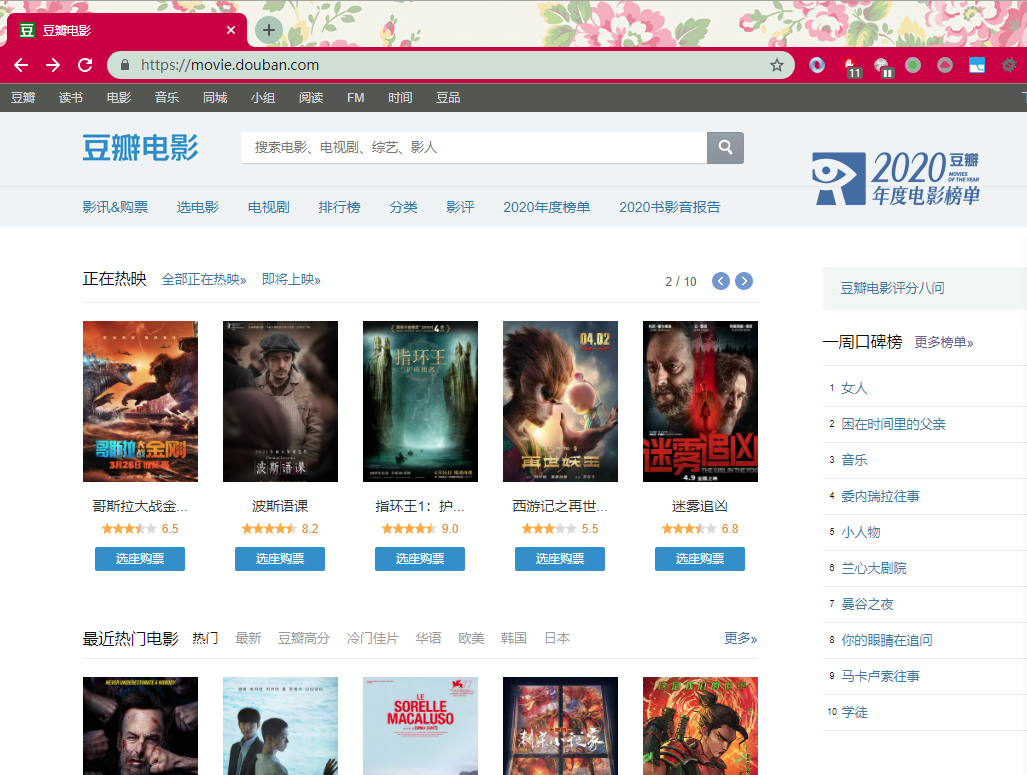
在谷歌浏览器输入[https://movie.douban.com/](https://movie.douban.com/) 打开豆瓣电影的页面,右键查看源代码,
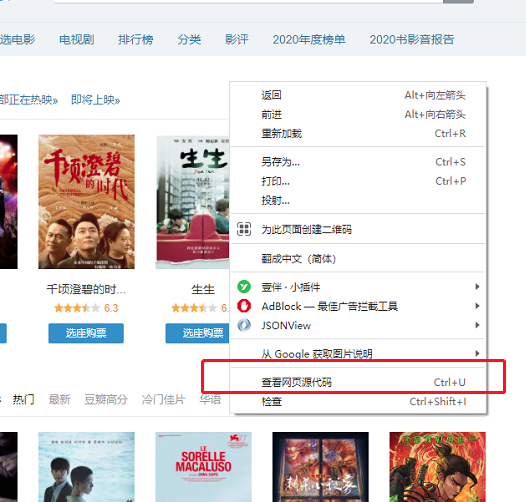
便会出现一个页面展示着原始的代码。这里的代码虽然很多,但本质上是 html、css、javascript 的组合,与我们刚刚演示的那个小网页没有区别。
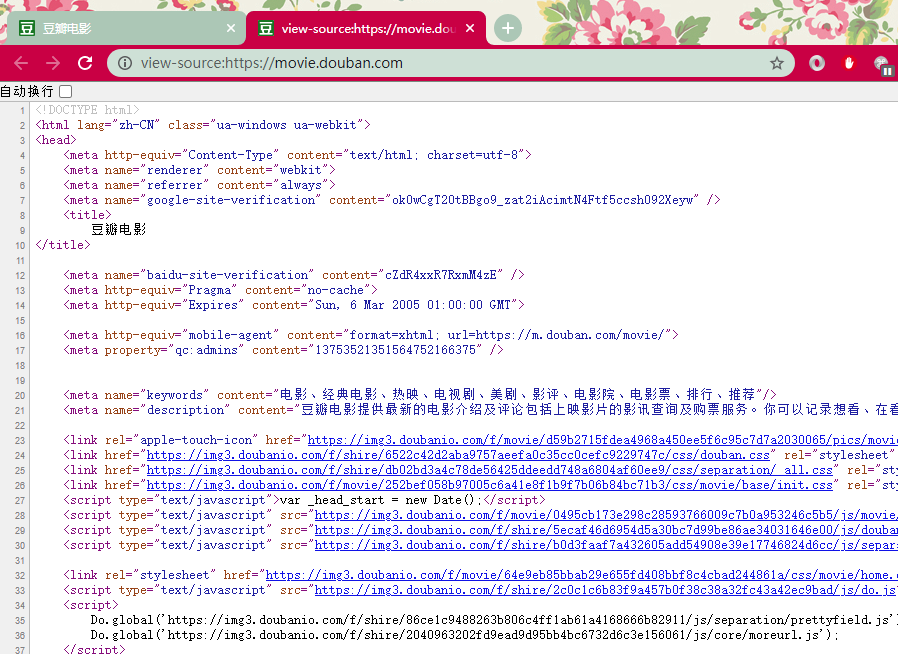
我们试着用 requests 来请求同样的数据。
requests 是 python 中专门处理 HTTP 请求的库,优雅的接口与易用性使其成为了 python 最流行的库之一。
首先是 requests 库的安装。
pip install requests
import requests
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('https://movie.douban.com/', headers={'User-Agent': agent})
# 返回的状态码
print('状态码:', response.status_code)
# 打印字符串数据
print(response.text)
在以上代码中,我们在请求中携带了浏览器信息以便尽可能地将自己伪装成人类,将获取到的进行解码后打印,从结果来看与我们从浏览器查看源码时所看到的无异。接下来我们按照一定规则便可提取到我们要的数据了。
状态码:200
<!DOCTYPE html>
<html lang="zh-CN" class="ua-mac ua-webkit">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">
<meta name="referrer" content="always">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<title>
豆瓣电影
</title>
<meta name="baidu-site-verification" content="cZdR4xxR7RxmM4zE" />
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Expires" content="Sun, 6 Mar 2005 01:00:00 GMT">
<meta http-equiv="mobile-agent" content="format=xhtml; url=https://m.douban.com/movie/">
<meta property="qc:admins" content="13753521351564752166375" />
<meta name="keywords" content="电影、经典电影、热映、电视剧、美剧、影评、电影院、电影票、排行、推荐"/>
......
了解 HTTP 协议
当我们在浏览器上打开一个页面时,浏览器需要向服务器请求展示这个页面所需要的信息。因为很多信息都是必须的,所以大家约定俗成地制定了一张“表格”,每次请求数据或返回数据时只要把“表格”上的留白依次填上就行。这张“表格”就是 HTTP 协议,它包含着 Accept(接收的媒体类型) 、 Accept-Charset(编码) 、Host(域名) 、User-Agent(浏览器和用户代理名称) 等等请求字段。关于一些爬虫所必须了解的字段我们会在之后的学习中逐步接触。
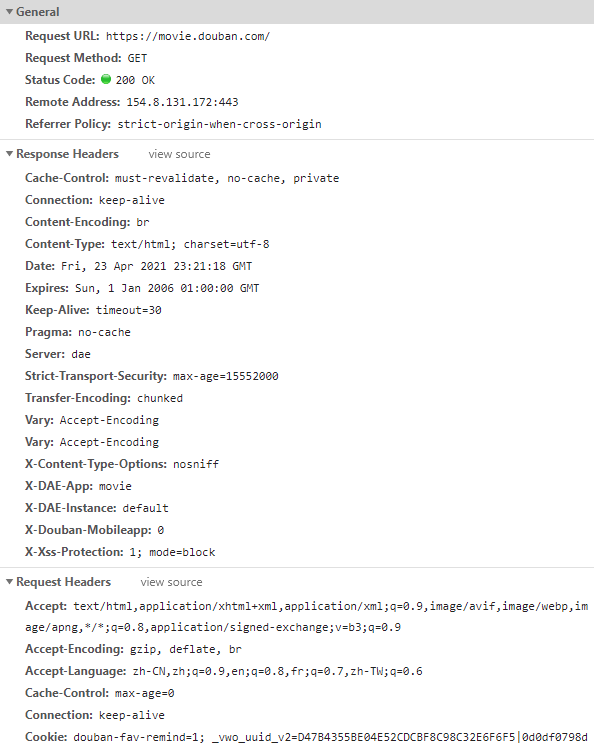
图为向豆瓣电影页面发起并返回数据的一个 HTTP 请求,包含了一些常见的请求与返回字段。
HTTP 请求方法
我们的代码中 requests.get('https://movie.douban.com/', headers={'User-Agent': agent}) 这行中的 requests.get 表示使用的是 HTTP 的 GET 方法。
我们上图中请求豆瓣电影页面时同样使用的是 GET 方法。

根据 HTTP 标准共有九种请求方法。
| 请求方法 | 描述 |
|---|---|
| GET | 获取资源 |
| POST | 新建资源 |
| PUT | 更新资源 |
| DELETE | 删除资源 |
| HEAD | 获取报头 |
| CONNECT | 代理连接 |
| OPTIONS | 查看链接状态 |
| TRACE | 用于测试或诊断 |
| PATCH | 局部更新资源 |
这些请求方法只是 HTTP 协议中的一个君子协定,具体所起的作用要看服务器上的代码。如果碰上个奇葩的程序员,很可能 GET 方法被用来删除数据,而 POST 方法却被用来获取页面数据。
HTTP 状态码
在我们的代码中 response.status_code 便是返回的状态码。 HTTP 协议中用状态码来表达服务器对于当前请求的响应状态。
我们常碰到的状态码有:
- 200:请求处理成功
- 301:资源发生了永久迁移,表示在浏览器上就是网页跳转
- 404:资源不存在,比如谷歌在国内打开就是 404
- 500:服务器错误
HTTP 的状态码被分成了 5 类,分别以数字 1、2、3、4、5 开头,均为 3 位的数字。
| 状态码 | 描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
图中的请求显示了 200 的状态码,表示请求处理成功。
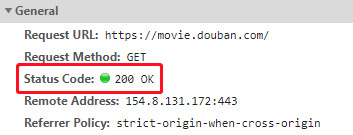
我们的代码中 response.status_code 打印出来的结果是 200, 也代表着代码执行的请求成功了。
评论
暂无评论