用 Beautiful Soup 解析豆瓣
浏览 1901
课文
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,强大的功能、健全的文档、友好的接口、不错的解析速度使得它成为现在最流行的 html 与 xml 的 python 解析库。
老规矩,先安装 Beautiful Soup 的库, 因为我们使用的解析模块是第三方的,所以要把解析库一并安装上。
pip install beautifulsoup4
pip install lxml
Beautiful Soup 有四种解析库,他们的优劣如下。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") | • Python内置标准库 <br/> • 执行速度适中 <br/> • 接口友好 | • 速度不如 lxml <br/>• 接口不如html5lib友好 |
| lxml HTML 解析器 | BeautifulSoup(markup,"lxml") | • 速度快<br/>• 接口友好 | • 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,"lxml-xml")<br/>BeautifulSoup(markup,"xml") | • 速度快<br/>• 唯一支持XML的解析器 | • 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | • 接口友好<br/>• 以浏览器的方式解析文档<br/>• 生成HTML5格式的文档 | • 速度慢 <br/>• 依赖第三方库 |
因为爬虫经常需要解析大量的 html 代码, 出于速度的考量我们之后统一使用 lxml HTML 解析器。
我们试着来解析一段简单的 html 代码。
from bs4 import BeautifulSoup
html_code = '''
<html>
<head>
<title>基本的网页</title>
<style type="text/css">
.word {
color: red;
}
.baidu {
color: green;
}
.sanyanya {
color: orange;
}
</style>
</head>
<body>
<p class="word">一个基本的网页</p>
<a class="baidu" href="https://baidu.com/" id="link1">百度</a>
<a class="sanyanya" href="https://3yya.com/" id="link2">三眼鸭</a>
</body>
</html>
'''
soup = BeautifulSoup(html_code, 'lxml')
# 以下两种方式是等价的
# 都是获取元素中第一个标签为 title 的元素
title = soup.title
print('标题元素:', title)
title = soup.find('title')
print('标题元素:', title)
first_p = soup.p
print('第一个 p 元素:', first_p)
# 通过 class 属性过滤元素
# 因为 class 是关键词,需要在后面加下划线
baidu_a = soup.find('a', class_='baidu')
print('第一个 class 为 baidu 的 a 元素:', baidu_a)
# 也可以将 class 约束放在字典中传入
sanyanya_a = soup.find('a', {'class': 'sanyanya'})
print('第一个 class 为 sanyanya 的 a 元素:', sanyanya_a)
# 不止是 class
# 能通过任何属性来过滤元素
print('id 属性为 link2 的元素:', soup.find(id='link2'))
# find_all 与 find 不同的是 find_all 返回的是一个数组对象
print('所有的 a 元素:', soup.find_all('a'))
# 通过 string 能获取元素的文本内容
print('标题内容:', title.string)
# 通过方括号来获取 class 属性
print('第一个 p 元素的 class 属性:', first_p['class'])
print('第一个 p 元素的父元素标签:', first_p.parent.name)
print('第一个 class 为 baidu 的 a 元素 href 属性:', baidu_a['href'])
print('第一个 class 为 sanyanya 的 a 元素文本内容:', sanyanya_a.string)
标题元素: <title>基本的网页</title>
标题元素: <title>基本的网页</title>
第一个 p 元素: <p class="word">一个基本的网页</p>
第一个 class 为 baidu 的 a 元素: <a class="baidu" href="https://baidu.com/" id="link1">百度</a>
第一个 class 为 sanyanya 的 a 元素: <a class="sanyanya" href="https://3yya.com/" id="link2">三眼鸭</a>
id 属性为 link2 的元素: <a class="sanyanya" href="https://3yya.com/" id="link2">三眼鸭</a>
所有的 a 元素: [<a class="baidu" href="https://baidu.com/" id="link1">百度</a>, <a class="sanyanya" href="https://3yya.com/" id="link2">三眼鸭</a>]
标题内容: 基本的网页
第一个 p 元素的 class 属性: ['word']
第一个 p 元素的父元素标签: body
第一个 class 为 baidu 的 a 元素 href 属性: https://baidu.com/
第一个 class 为 sanyanya 的 a 元素文本内容: 三眼鸭
我们还可以用 get_text() 方法获得代码中的纯文本。
print(soup.get_text())
基本的网页
一个基本的网页
百度
三眼鸭
同样的道理,这里只是介绍了一些基本的用法,学编程不是背字典,更多的知识点我们会在之后的学习当中逐步接触。
爬取豆瓣电影 Top250
简单的认识 Beautiful Soup 之后我们就来到实战部分了,希望这一步没有来得太快。
打开豆瓣的 top250 页面,[https://movie.douban.com/top250](https://movie.douban.com/top250)。
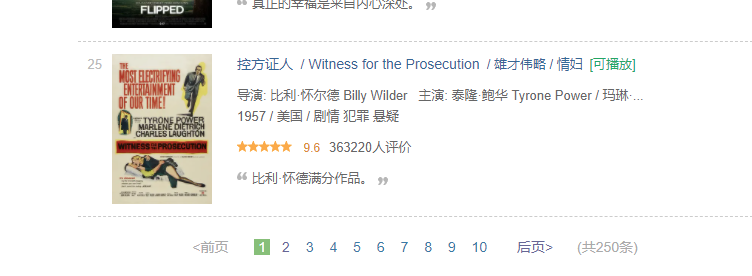
可以看到页面是采用分页器的形式,一般来说如果页面是采用分页器的形式,我们则需要用 Beautiful Soup 解析页面代码的方式来提取数据。如果是采用上拉加载或点击加载更多的形式,则可以通过寻找 API 接口的形式来爬取数据。这种判断方法不绝对,但大部分情况下还是可以这么判断的。
右键列表的电影图片,点击检查调出我们的开发者工具,此时开发者工具默认选中的元素就是我们右键的图片元素。
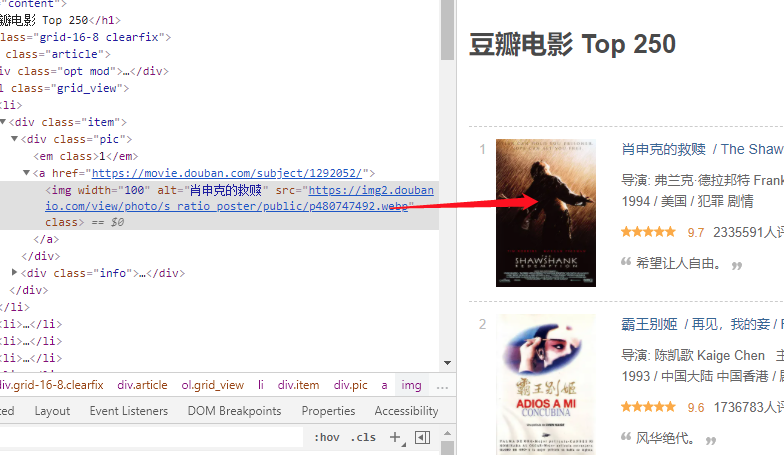
我们将鼠标在左边的 HTML 元素上移动,会发现右边的页面元素会出现一个高亮的状态,这表示你当前鼠标所在的 HTML 元素便是高亮的页面元素。

我们在图中看到,可以用 div 元素 + class 属性为 item 这两个约束条件来寻找到每行的电影元素。
from bs4 import BeautifulSoup
import requests
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get(
f'https://movie.douban.com/top250',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
soup = BeautifulSoup(response.content, 'lxml')
print(len(soup.find_all('div', {'class': 'item'})))
first_movie = soup.find_all('div', {'class': 'item'})[0]
print(first_movie)
状态码: 200
25
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2335591人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
总共找到了 25 个对应的元素,与每页中有 25 条电影是一致的,而且也打印了第一条肖申克的救赎的电影信息。
提取其中的元素
接着我们要试着从电影元素中来提取诸如电影名、评分、评价数、封面图片等信息。
通过我们的观察,我们分析出了这几条各自所处的元素:
电影名: <span class="title">肖申克的救赎</span>
评分:<span class="rating_num" property="v:average">9.7</span>
评价数:<span>2335591人评价</span>
短介绍:<span class="inq">希望让人自由。</span>
封面:<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
好了,让我们尝试着从 HTML 结构中解析出这些东西吧,如上面提到的,先确定约束条件。
电影名比较简单,我们只需用 span 标签与 class 属性为 title 这两个约束条件,找到后打印元素的 text 内容。
虽然中文电影名与英文电影名都是 span 标签与 class 属性为 title,但我们直接用 find 提取的就是第一个元素也就是中文电影名,无需过多处理。
print('电影名:',first_movie.find('span', {'class': 'title'}).string)
电影名:肖申克的救赎
注意我们这里是 first_movie.find 而不是 soup.find,确保了我们是在一个电影的元素中寻找而不是在整个页面中搜索。
然后是评分、短介绍、封面:
print('评分:', first_movie.find('span', {'property': 'v:average'}).string)
print('短介绍:', first_movie.find('span', {'class': 'inq'}).string)
print('封面:', first_movie.find('img')['src'])
评分: 9.7
短介绍: 希望让人自由。
封面: https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg
这里我们略过了评论数,因为 <span>2335591人评价</span> 有点特殊,它没有一个特定的标签或属性使得我们将它与其他元素区分开来。
但它前面刚好有一个元素 <span content="10.0" property="v:best"></span> 属性比较特殊,我们可以先找到这个元素再找下一个元素从而找到评论数。
print('评价数:', first_movie.find('span', {'property': 'v:best'}).find_next().string[:-3])
评价数: 2336323
我们还有另一种方法,就是使用正则表达式。
import re
print('评价数:', first_movie.find(string=re.compile('.*人评价')).string[:-3])
评价数: 2336323
由于正则表达式是一个比较系统且独立的知识点,所以这里就不再赘述,对于正则表达式的学习可以参考其他文档。
不过我们假设一种极端情况,如果电影名为xxx评价数,就会导致正则匹配错误,匹配到电影名去了,所以我们要再加一个约束条件,限制 class 属性不存在,与电影名元素区分开来。
修改为:
print('评价数:', first_movie.find(string=re.compile('.*人评价'), class_=None).string[:-3])
修改一下代码,用 find_all 查找出所有的电影,并解析数据后打印。
from bs4 import BeautifulSoup
import requests
import re
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get(
f'https://movie.douban.com/top250',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
soup = BeautifulSoup(response.content, 'lxml')
movies = soup.find_all('div', {'class': 'item'})
print('元素个数:', len(movies))
for movie in movies:
print('电影名:', movie.find('span', {'class': 'title'}).string)
print('评分:', movie.find('span', {'property': 'v:average'}).string)
print('短介绍:', movie.find('span', {'class': 'inq'}).string)
print('封面:', movie.find('img')['src'])
print('评价数:', movie.find(string=re.compile('.*人评价'), class_=None).string[:-3])
PS E:\代码> python .\test2.py
状态码: 200
电影名: 肖申克的救赎
评分: 9.7
短介绍: 希望让人自由。
封面: https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg
评价数: 2336323
电影名: 霸王别姬
评分: 9.6
短介绍: 风华绝代。
封面: https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg
评价数: 1737336
电影名: 阿甘正传
评分: 9.5
短介绍: 一部美国近现代史。
封面: https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2372307693.jpg
评价数: 1758629
......
自动翻页的蜘蛛
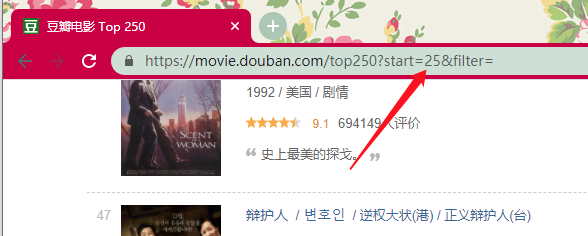
点击其他的页面,我们发现页面链接是通过改变 start 参数的方式来达到的。平均每页有 25 条电影数据,到下一页时 start 便加上 25。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
......
第十页:https://movie.douban.com/top250?start=225&filter=
我们便可以简单地配合一个 for 循环,来完成一个自动翻页读取数据的过程。
import requests
import re
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
for start in range(0, 225, 25):
print('start:', start)
response = requests.get(
f'https://movie.douban.com/top250?start={start}',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
soup = BeautifulSoup(response.content, 'lxml')
movies = soup.find_all('div', {'class': 'item'})
print('元素个数:', len(movies))
for movie in movies:
print('电影名:', movie.find('span', {'class': 'title'}).string)
print('评分:', movie.find('span', {'property': 'v:average'}).string)
print('短介绍:', movie.find('span', {'class': 'inq'}).string)
print('封面:', movie.find('img')['src'])
print('评价数:', movie.find(string=re.compile('.*人评价'), class_=None).string[:-3])
......
电影名: 东邪西毒
评分: 8.6
短介绍: 电影诗。
封面: https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1982176012.jpg
评价数: 483609
电影名: 寄生虫
评分: 8.8
Traceback (most recent call last):
File ".\test2.py", line 28, in <module>
print('短介绍:', movie.find('span', {'class': 'inq'}).string)
AttributeError: 'NoneType' object has no attribute 'string'
可是这会我们却碰到了一个报错,显示找不到短介绍返回的结果为 None。

我们看一下电影页,发现原来是寄生虫这部电影没有短介绍,我们单独针对这种情况判断一下。
将 print('短介绍:', movie.find('span', {'class': 'inq'}).string) 修改为:
short_intro = movie.find('span', {'class': 'inq'})
print('短介绍:',short_intro.string if short_intro else '')
再次执行代码成功运行到结束。
我们将数据保存到 csv 文件,修改我们的代码如下:
import csv
import os
from bs4 import BeautifulSoup
import requests
import re
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
data = []
for start in range(0, 225, 25):
print('start:', start)
response = requests.get(
f'https://movie.douban.com/top250?start={start}',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
soup = BeautifulSoup(response.content, 'lxml')
movies = soup.find_all('div', {'class': 'item'})
print('元素个数:', len(movies))
for movie in movies:
short_intro = movie.find('span', {'class': 'inq'})
data.append(
{
'title': movie.find('span', {'class': 'title'}).string,
'rate': movie.find('span', {'property': 'v:average'}).string,
'short_intro': short_intro.string if short_intro else '',
'cover': movie.find('img')['src'],
'rate_count': movie.find(string=re.compile('.*人评价'), class_=None).string[:-3],
}
)
with open('TOP250电影.csv', mode='w', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(
f, delimiter=',', fieldnames=['电影名', '评分', '短介绍', '评价数', '封面']
)
writer.writeheader()
for row in data:
writer.writerow(
{
'电影名': row['title'],
'评分': row['rate'],
'短介绍': row['short_intro'],
'评价数': row['rate_count'],
'封面': row['cover'],
}
)
结果:
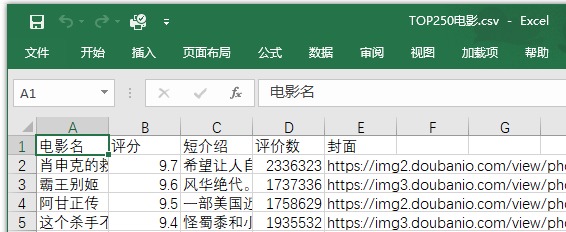
保存封面图片
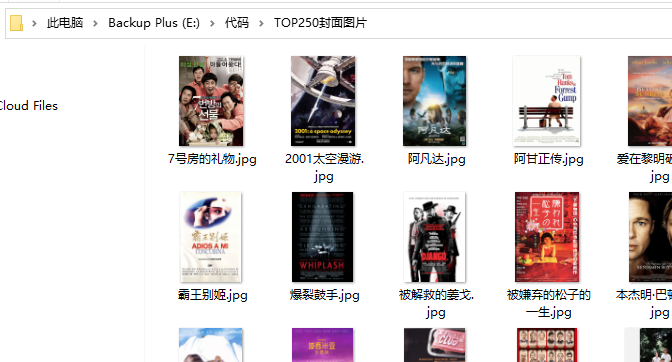
通过 requests.get 方法可以直接获取到图片的二进制数据,用 mode='wb' 的方式打开文件,将其写入硬盘便可以了。
# 判断目录是否存在,不存在则创建
if not os.path.exists('TOP250封面图片'):
os.makedirs('TOP250封面图片')
for row in data:
print('保存{title}的封面中...'.format(title=row['title']))
response = requests.get(row['cover'])
with open('TOP250封面图片/' + row['title'] + '.jpg', mode='wb') as f:
f.write(response.content)
充电宝
2021-10-31
充电宝
2021-10-31
充电宝
2021-10-31
充电宝
2021-10-31