用 selenium 爬取花瓣网
浏览 1607
课文
这个章节我们来爬取一些有难度的网站,比如需要登录的花瓣网。
由于 requests 并不能执行 JavaScript,而登录行为往往是通过复杂的 JavaScript 行为实现的,这使得我们如果要用 requests 来请求登录后的数据,就得逆向页面的 JavaScript 代码, 分析登录中所执行的 HTTP 请求,再用 reqeusts 来逐步模拟登录行为,如果遇到验证码难度更是指数级上升。这使得用 requests 来模拟登录很多时候是一个不划算的方法。
这会我们就需要聊聊 selenium 这个工具了。
学习 selenium
selenium 原本是一款为自动化测试而开发的工具,近几年的时间则被更多的爬虫爱好者所发掘。selenium 有着类似 Beautiful Soup 的解析模块,还能与网站上的文本、按钮之类的元素交互,执行输入、点击之类的动作。
因为 selenium 的本质在于,它会使用一个浏览器来搭载网页,意味着能执行网页中的 JavaScript 代码。并且我们可以通过代码控制selenium 来模拟人类行为,这使得我们使用 selenium 能绕过很多针对爬虫所设计的陷阱与反爬措施。
selenium 的安装
同之前的很多第三方库一样,我们可以用 pip 来安装 selenium。
pip install selenium
之后我们需要下载对应的浏览器驱动。
| 驱动 | 下载地址 |
|---|---|
| Chrome | 官方下载</br>淘宝镜像下载 |
| Edge | 官方下载 |
| Firefox | 官方下载 |
| Safari | 官方下载 |
在 windows 系统,下载驱动完成后需要将驱动所处的目录加入到环境变量当中。
- 右键我的电脑属性

- 在关于标签页中打开高级系统设置。

- 点开
环境变量, 找到Path变量,点击编辑。
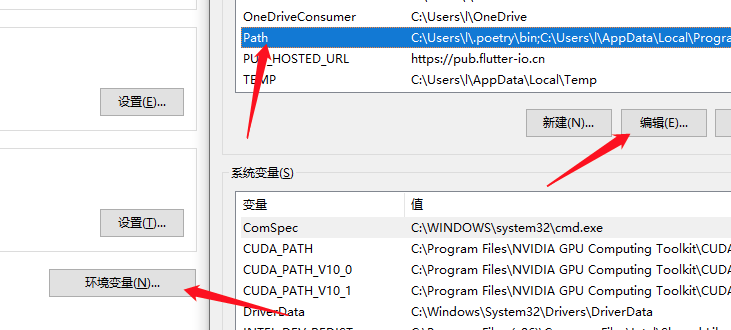
- 点击新建,输入
浏览器驱动所处的目录后点击确定。

- 重启编辑器。
我们依旧以 Chrome 浏览器为例,执行以下代码。
from selenium import webdriver
browser = webdriver.Chrome()
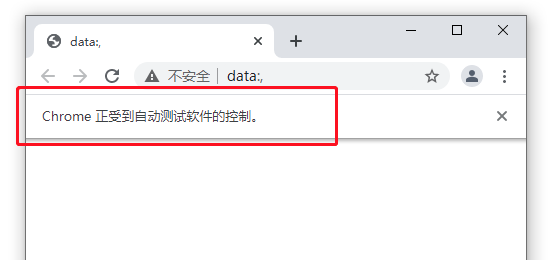
执行后会显示一个测试中的 Chrome 浏览器,selenium 运行的浏览器一个显著特征是会显示 浏览器正受到自动测试软件的控制。
用 selenium 爬取花瓣
打开花瓣网的发现页面 [https://huaban.com/discovery/](https://huaban.com/discovery/)。当我们往下滑动页面加载更多时,会发现很快就需要登录。
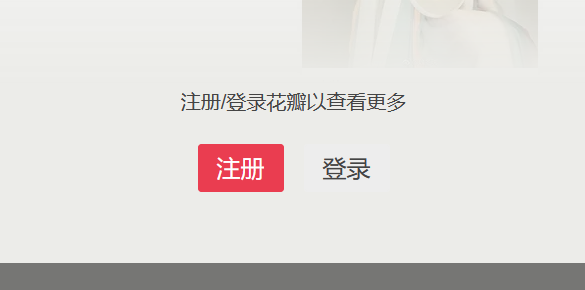
于是乎,就到 selenium 的 showtime 了。用 selenium 打开花瓣的发现页
from selenium import webdriver
browser = webdriver.Chrome()
# 打开花瓣发现页
browser.get('https://huaban.com/discovery/')
在登录之前我们试着用 selenium 来获取一下发现页中的元素,依旧是右键检查,可以看到所有的图片元素都存在于一个 id 为 waterfall 的 div 中。
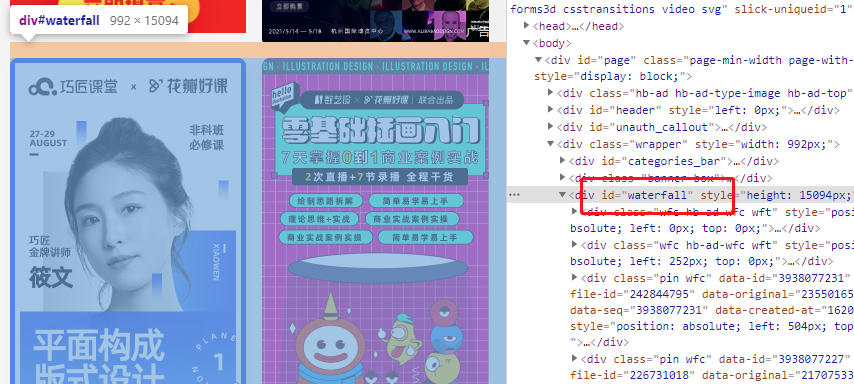
selenium 与 Beautiful Soup 很类似,都是通过 id 、class 等各种属性来建立约束条件,通过这些约束条件来定位元素。
懒得学习新知识的同学,可以直接获取网页的源代码,用 Beautiful Soup 来进行解析。
from bs4 import BeautifulSoup
soup = BeautifulSoup(browser.page_source, 'lxml')
# 使用 BeautifulSoup 解析元素
# .....
不过这里默认各位都是勤奋好学的同学,所以我们还是讲讲如何使用 selenium 定位元素。
selenium 定位元素有以下几种方法。
- find_element_by_id:通过 id 定位
- find_element_by_name: 通过 name 属性定位
- find_element_by_xpath:通过 xpath 表达式定位
- find_element_by_link_text:通过文本寻找链接
- find_element_by_partial_link_text:通过部分文本寻找链接
- find_element_by_tag_name:通过标签定位元素
- find_element_by_class_name:通过类名定位元素
- find_element_by_css_selector:通过 css 选择器定位元素
以上的定位方法都是只定位匹配到的第一个元素,如果我们想返回所有匹配到的元素只需将方法中的 element 加个 s 。
以下方法返回的是所有匹配到的元素。
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
详细的定位方法可以参考文档 https://selenium-python.readthedocs.io/locating-elements.html
回到谷歌浏览器开发者工具,观察我们要提取的元素有什么特殊标记。
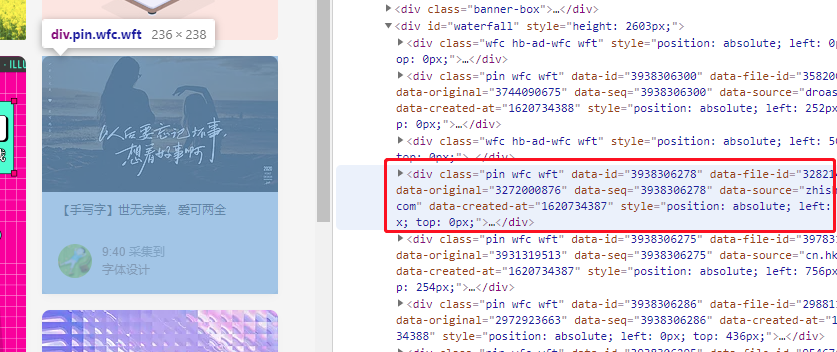
它是一个 div 元素,它的 class 属性中拥有 wfc 属性,它有 data-id 、 data-file-id 、data-original 等看起来比较特殊的属性。以上的点都可以作为我们的约束条件来过滤元素,我们这里无需过多约束,只选择 div 元素与有着 data-id 属性这两个点应该足够了,试试看。
这里我们采用 css 选择器 的方式,那就应该写作 div[data-id] 。
_有关 css 选择器可以参考 https://www.w3school.com.cn/cssref/css_selectors.asp _
回到我们的代码,改写成以下的模样。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://huaban.com/discovery/')
waterfall = browser.find_element_by_id('waterfall')
items = waterfall.find_elements_by_css_selector('div[data-id]')
我们再通过 img 元素与 alt 属性来定位图片。
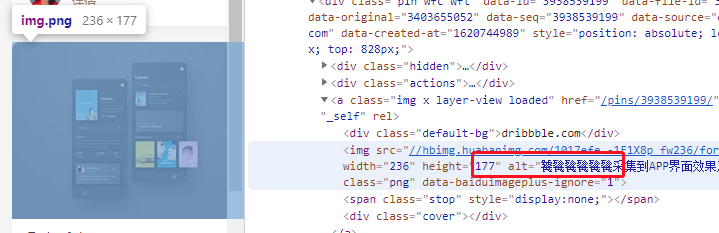
我们通过 for 循环来遍历刚刚找到的元素,再通过一个 css 选择器 来提取图片,img[alt] 意味着选择一个拥有 alt 属性的 img 元素。最后用 get_attribute('src') 来获取图片地址。
for item in items:
print(item.find_element_by_css_selector('img[alt]').get_attribute('src'))
运行我们的程序。
DevTools listening on ws://127.0.0.1:11172/devtools/browser/45ee5555-9c08-44c8-8e04-7099563db0d4
https://hbimg.huabanimg.com/1290bcb364da4569595edd0f484d1ea0daff16c7aa762-ZVKyI7_fw236/format/webp
https://hbimg.huabanimg.com/a7b19bb1d9ce91361776d0ff561041c7198b842f77ce-Muz8x9_fw236/format/webp
https://hbimg.huabanimg.com/5da78381b66fb3e6a61fb735ff0449f6bc87f9fb771dc-Ldnc0j_fw236/format/webp
https://hbimg.huabanimg.com/b71024ff675599b979eb7e4772dbe738ff2ad3242be4ca-5BYNr1_fw236/format/webp
https://hbimg.huabanimg.com/ceebca76add88af28f0bb05cb4df106a5672dffd7d184-ttBtMH_fw236/format/webp
https://hbimg.huabanimg.com/e1cb24f93f9ec7d0d70ecc9a4f24103c494a25f9b7cc2-gvZuc4_fw236/format/webp
https://hbimg.huabanimg.com/cdfec10789b52e6ac777d0b35d5683c1a12e519581d94-EHiXOb_fw236/format/webp
......
用 selenium 解决登录问题
我们到这一步还只是用 selenium 抓取了图片链接,并没有解决一开始碰到的登录问题。这次我们要在登录之后再抓取数据。
我们需要在程序爬取数据之前“暂停一下”,等待我们完成登录的过程,于是可以加入 input('登录完成后按回车:') 这行代码。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://huaban.com/discovery/')
input('登录完成后按回车:')
waterfall = browser.find_element_by_id('waterfall')
items = waterfall.find_elements_by_css_selector('div[data-id]')
for item in items:
print(item.find_element_by_css_selector('img[alt]').get_attribute('src'))
运行程序,在网页中登录,回到控制台按回车。虽然程序照常输出了爬取到的链接,但这些链接依旧只是一页的内容。我们登录的目的是为了能源源不断地爬取到当向下滑动滚动条时页面加载出来的图片。
selenium 控制页面滚动
JavaScript 里可以通过 scrollIntoView 方法来将一个元素滚动到可见区域,我们只需让 selenium 执行这段代码,将当前图片瀑布流中的最底下一个元素滚动到歌曲区域,便可模拟人为的下滑滚动条加载更多。注意在滚动之后,我们要小小等一会,以便页面加载完数据,加入一行 time.sleep(3)。
最终代码
import os
import time
from selenium import webdriver
import requests
browser = webdriver.Chrome()
browser.get('https://huaban.com/discovery/')
input('登录完成后回车:')
waterfall = browser.find_element_by_id('waterfall')
print(waterfall)
data = set()
# 爬取 page 页的数据
page = 10
for _ in range(page):
items = waterfall.find_elements_by_css_selector('div[data-id]')
for item in items:
url = item.find_element_by_css_selector('img[alt]').get_attribute('src')
print(url)
data.add(url)
# 将页面滚动到底部
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(3)
path = '花瓣网图片'
if not os.path.exists(path):
os.makedirs(path)
for index, url in enumerate(data):
print(f'下载第 {index} 张图片中...')
response = requests.get(url)
with open(os.path.join(path, str(index) + '.jpg'), mode='wb') as f:
f.write(response.content)
评论
暂无评论