selenium + requests 爬取知乎美女头像
浏览 1922
课文
从知乎的哪个页面能源源不断地获取到用户头像呢?
试想我们刷推荐页时是不是可以一直能刷到新回答,通过这些回答我们就能源源不断地获取到用户头像。对于知乎,同样是需要我们登录才能进行操作,我们打开知乎的推荐页面 https://www.zhihu.com/index,如果没登录的情况下会跳到登录页面。

对于需要爬取登录的页面一般有三个处理方法。
| 方法 | 优势 | 劣势 |
|---|---|---|
| 分析 http 请求,使用 requests 模拟登录,获取 cookies 之后模拟登录。 | 速度快 | 分析请求难度高,难以处理验证码登录。 |
| 使用 selenium 调用浏览器,手动登录之后爬取数据。 | 操作简单,可以手动处理验证码。 | 速度慢 |
| 使用 selenium 调用浏览器手动登录,保存 cookies,用 requests 携带 cookies 爬取数据。 | 速度快,操作简便 | 有些情况不适用 |
对于花瓣网我们采用的是第二种方法,全程用 selenimu 处理登录与数据的爬取。对于知乎我们尝试第三种方法,就是 selenimu 手动登录后获取带登录信息的 cookies,再使用 requests执行数据的爬取。
selenimu 登录知乎
二话不说先上 selenimu 。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/signin')
可是在我们登录时,会发现登录不上。
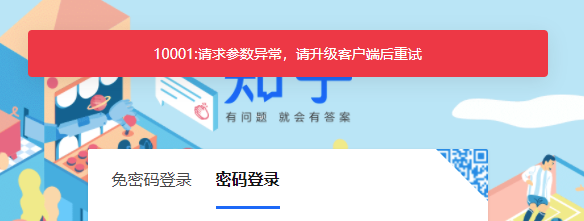
这是因为知乎通过检测浏览器的特征,发现了我们是使用的 selenium 运行的浏览器进行的登录,因此拒绝了我们的登录,这是知乎的反爬机制之一。
那我们有什么应对方法吗?
我们可以通过用正常的浏览器来打开知乎,用 selenium 连接正常的浏览器进行调试,这样就可以绕开知乎的反爬机制了。
import os
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
os.system('start Chrome --remote-debugging-port=9222')
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(options=options)
browser.get('https://www.zhihu.com/signin')
如果你出现下图的提示,可以尝试在 os.system 中把 Chrome 替换成绝对路径,或者最好按照上章节的内容,将 Chrome 所在路径加入 windows 的 PATH 变量。

获取知乎推荐的接口
在登录后知乎推荐页面右键检查,打开 Network 标签,点击 XHR 过滤, 往下滚动页面,触发网页加载数据。这会我们能看到 Network 中会出现一些网络请求。
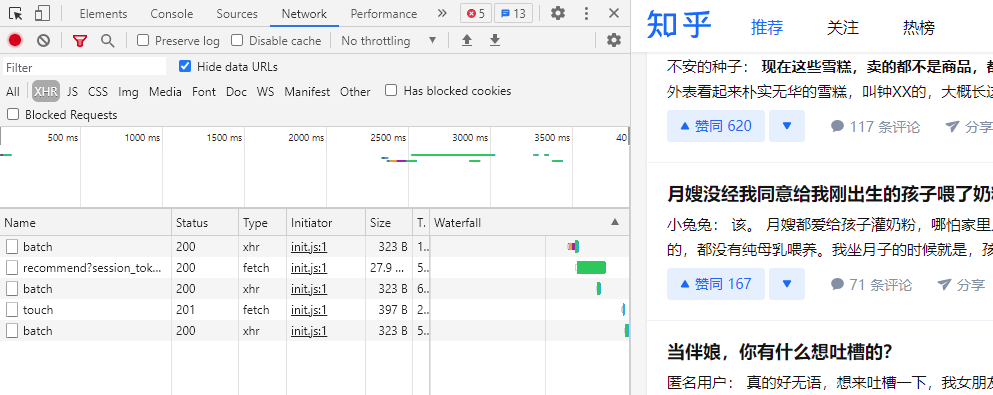
点击这些请求, 会发现 Name 为 batch 的请求并没有在 response 中返回数据, 而只有 recommend 请求中返回了数据。
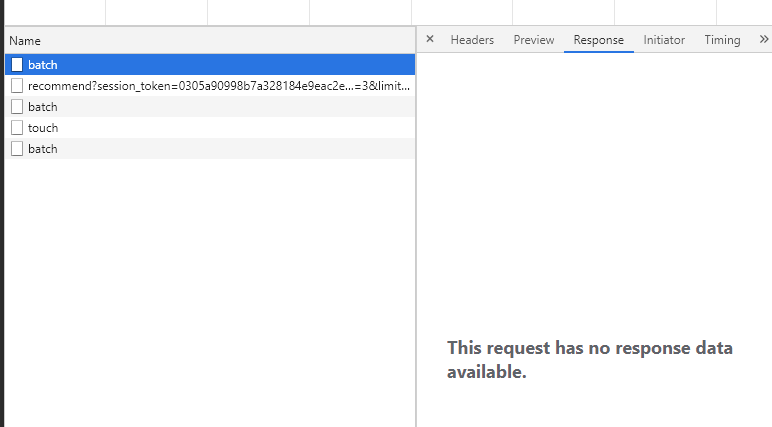

将 recommend 的请求链接复制到浏览器打开,可以看到返回了数据, 可以断定 recommend 这个请求正是知乎用来加载数据的请求。

如果我们把这个请求链接复制到一个未登录知乎的浏览器中,比如打开一个新的无痕浏览器。
会发现同样的一个请求链接却无法返回数据,这是因为登录信息是保存在 cookie 当中,而打开的无痕浏览器由于并未登录知乎,所以没有登录信息,导致无法获取到数据。
分析接口中参数的含义
让我们多滚动下页面,接着从 Network中找两个紧邻的接口调用的请求来对比下。

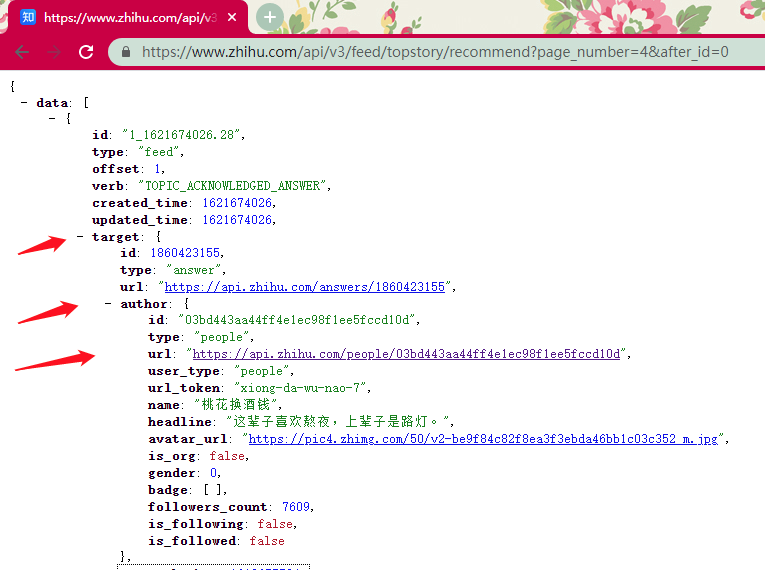
接口 1:
接口 2:
很多同学都是看了几百集柯南过来的,让我们借用下柯南的推理能力。
session_token 应该是 session 的凭证,page_number 与 after_id 这两个比较像控制数据页数的参数,因为它们是唯一改变的量, page_number 是每次加 1, after_id 是每次加 6, 因为每页返回的数据条数是 6 条。
经进一步的测试, 我们发现把其他参数都去掉只保留 page_number 与 after_id 依旧是可以获取到数据的,这样子就不需要费劲去获取 session_token 的值了,它并不是一个必须的参数。
到目前为止,我们应该修改 page_number 与 after_id 来获取更多数据,但其实这两个参数也可以去掉,只保留 https://www.zhihu.com/api/v3/feed/topstory/recommend 每次刷新返回的也是新数据。
这可能是知乎后端接口升级,不再需要这些参数了,但前端代码未更改,所以调用时仍然有这些参数的原因。
用 fake_useragent 生成 User-Agent
之前的 User-Agent 都是从浏览器的请求中复制的,这次我们使用 fake_useragent 这个库来生成一个 User-Agent。
pip install fake-useragent
fake_useragent 可以生成模拟一些浏览器的 User-Agent 信息,或者生成一个随机的 User-Agent 信息。
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.ie)
print(ua.chrome)
print(ua.firefox)
print(ua.random)
Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1623.0 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; rv:22.0) Gecko/20130405 Firefox/22.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36
用 requests 请求数据
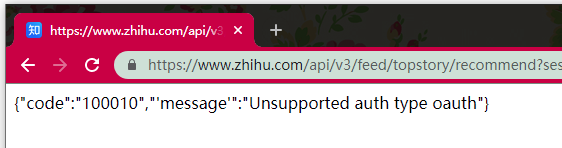
我们先尝试着不带登录来获取数据,会发现是失败r
import requests
from fake_useragent import UserAgent
ua = UserAgent()
response = requests.get(
'https://www.zhihu.com/api/v3/feed/topstory/recommend',
headers={'User-Agent': ua.random},
)
print(response.status_code)
print(response.text)
401
{"code":"100010","'message'":"Unsupported auth type oauth"}
这是因为没有携带 cookie 中的登录信息,我们尝试着先在 selenium 中先手动完成登录,接着再使用 selenium 中的 cookies 完成信息的爬取。
在这之前我们先打印看一下 selenium 能获取到的 cookies 格式。
import os
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
os.system('start Chrome --remote-debugging-port=9222')
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(options=options)
browser.get('https://www.zhihu.com/signin')
input('登录完成后回车:')
print(browser.get_cookies())
[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': 'KLBRSID', 'path': '/', 'secure': False, 'value': 'd1f07ca9b929274b65d830a00cbd719a|1621633798|1621633790'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1621633798'}, {'domain': 'www.zhihu.com', 'expiry': 2147483647, 'httpOnly': False, 'name': 'YD00517437729195%3AWM_NIKE', 'path': '/', 'secure': False,
'value': '9ca17ae2e6ffcda170e2e6eeadc25df8bdfa8bb56e87868ab6d44a839a9b84ae61fcbc9e97c621b6e9b985e22af0fea7c3b92ab6e7a78cd95fac93a2b9f96bb788a396c472f8e9a5a9b77df7b3a98ee95bf3948ba5b446b5e8bad3e721b49aa9b8ce67b5e88ebbf44fb7b786a7dc3b85bf9683aa54afb48eb3e762b48aa290fb65b09dffccb35cbbb4a0b8db5cad8789bac96bf4babd95c6339b99aa8bfc69e9ed96aacf7395ad98a5ec3bf2ba8fd8aa4093ee9ed1c837e2a3'}, {'domain':
......
selenium 的 get_cookies 方法返回的是一个数组,然而 requests 中的 cookies 需要的是一个字典,应该怎么处理呢?
我们发现 get_cookies 返回的数组中每一个元素都是有相同的键的字典, domain 是它的域名,name 与 value 是 cookies 中的名称与值, 对应到 requests 的 cookies 中正是字典的键与值。
我们用一行代码将其做一个转换。
cookies = {item['name']: item['value'] for item in browser.get_cookies()}
print(cookies)
{'SESSIONID': '3gEgBHCHZWUqgj3736824OvBHdnuVoHGyjekfKytnWr', 'KLBRSID': '57358d62405ef24305120316801fd92a|1621634134|1621634130', 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49': '1621634133', 'osd': 'VFgXAkn81uzZjbsSVfuUs40d24JAybOqvcv1Ux6ih7ur6dUnYK77RL6PvxNVnwO7ErO5iH1fYT2RaTkXjvqpZAM=', 'YD00517437729195%3AWM_NIKE': '9ca17ae2e6ffcda170e2e6eeadc25df8bdfa8bb56e87868ab6d44a839a9b84ae61fcbc9e97c621b6e9b985e22af0fea7c3b92ab6e7a78cd95fac93a2b9f96bb788a396c472f8e9a5a9b77df7b3a98ee95bf3948ba5b446b5e8bad3e721b49aa9b8ce67b5e88ebbf44fb7b786a7dc3b85bf9683aa54afb48eb3e762b48aa290fb65b09dffccb35cbbb4a0b8db5cad8789bac96bf4babd95c6339b99aa8bfc69e9ed96aacf7395ad98a5ec3bf2ba8fd8aa4093ee9ed1c837e2a3',
......
成功转换成了 requests 所需的字典的格式,一大串的数据看着恐怖,我们也无需分析其中每个键表示的什么信息,只需知道其中包含着我们的登录信息,之后只需一股脑地都带上就行。
import os
import requests
from fake_useragent import UserAgent
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
os.system('start Chrome --remote-debugging-port=9222')
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(options=options)
browser.get('https://www.zhihu.com/signin')
input('登录完成后回车:')
cookies = {item['name']: item['value'] for item in browser.get_cookies()}
ua = UserAgent()
response = requests.get(
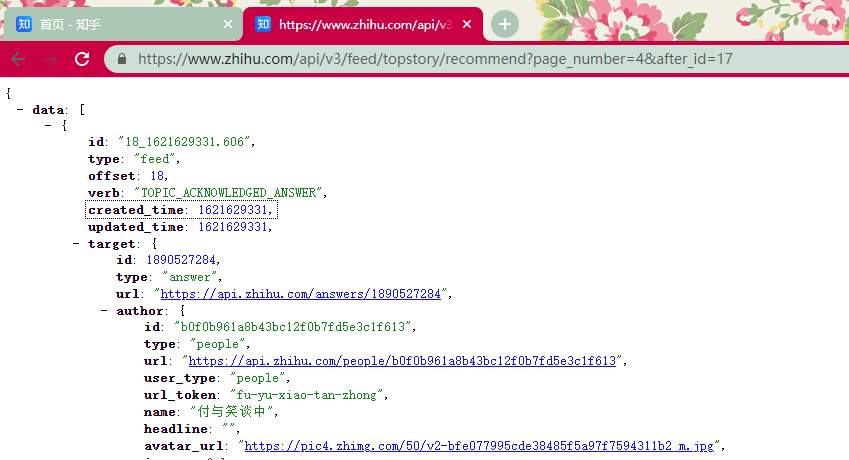
'https://www.zhihu.com/api/v3/feed/topstory/recommend?page_number=4&after_id=17',
headers={'User-Agent': ua.random},
cookies=cookies,
)
print(response.status_code)
print(response.text)
登录完成后回车:
200

保存用户头像
我们已经能从接口获取到数据了,接下来就是把用户的头像保存到本地。回到网页,我们来分析一下接口返回的数据。
每次返回的数据总共有 6 条, 会存放在 data 这个元素中。

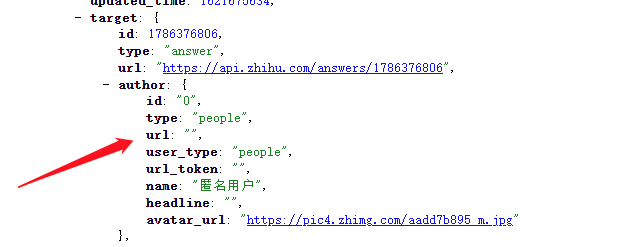
展开 data 中的第一个元素, 我们能看到作者的数据存在于 target 元素下的 author 元素当中,
但是经我的对比,这里数据中的 gender 在男性用户时为 1 ,在女性或未标明性别时都为 0 , 这对我们筛选帅哥美女是不利的,但我们可以通过 url 这个数据链接进一步获取详细的用户信息。
打开 url后能获取到详细的用户信息, name 表示用户名, avatar_url 表示头像链接, gender 表示性别, 0 为女性、 1 为男性、 -1 为未标明性别,关于 gender 的含义可以通过多对比几个用户信息得出。
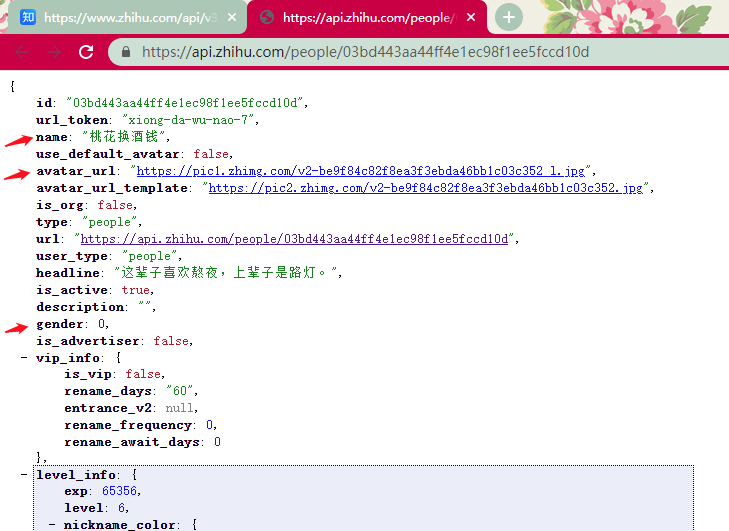
我们还需要过滤掉机构号与匿名用户, type 为 people 时代表为个人用户,当为匿名用户时, url 元素为空字符串。
还有一点就行,对于获取到的头像链接,比如: https://pic3.zhimg.com/v2-d24d80fc29a1b117cf7a7fe027f6d3b5_l.jpg , 直接打开会是一个小图,
{kind=link}

但如果我们把链接中的 _l 去掉,就能获取到一张原图。

最终代码
import os
import requests
from fake_useragent import UserAgent
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
os.system('start Chrome --remote-debugging-port=9222')
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(options=options)
browser.get('https://www.zhihu.com/signin')
input('登录完成后回车,如果已是登录状态直接回车:')
cookies = {item['name']: item['value'] for item in browser.get_cookies()}
ua = UserAgent()
# 图片保存路径
path = '知乎头像'
# 0 为女性用户
# 1 为男性用户
# -1 为未标注性别
# 这里爬取美女的头像
gender = 0
# 判断目录是否存在,不存在则创建
if not os.path.exists(path):
os.makedirs(path)
# 爬取 20 x 6 = 60 条数据
for _ in range(20):
response = requests.get(
'https://www.zhihu.com/api/v3/feed/topstory/recommend',
headers={'User-Agent': ua.chrome},
cookies=cookies,
)
if response.status_code != 200:
print('获取数据出错')
continue
for item_data in response.json()['data']:
user_data = item_data['target']['author']
if user_data['type'] != 'people':
print('非用户类型')
continue
if user_data['url'] == '':
print('匿名用户')
continue
response = requests.get(
user_data['url'],
headers={'User-Agent': ua.random},
cookies=cookies,
)
if response.status_code != 200:
print('获取数据出错')
continue
detail_data = response.json()
if detail_data['gender'] != gender:
continue
print(f'保存{detail_data["name"]}的头像中...')
# 获取原图
avatar_url = detail_data['avatar_url'].replace('_l', '')
image_response = requests.get(avatar_url)
if image_response.status_code != 200:
print('获取数据出错')
continue
with open(os.path.join(path, detail_data['name'] + '.jpg'), mode='wb') as f:
f.write(image_response.content)
登录完成后回车,如果已是登录状态直接回车:
匿名用户
保存闲杂人士的头像中...
保存吃货一枚的头像中...
保存齐木楠子的头像中...
保存青雀的头像中...
匿名用户
保存叮咚在云上的头像中...
获取数据出错
保存啊落英缤纷的头像中...
......

评论
暂无评论