请求豆瓣 API 接口数据
浏览 2709
课文
概括性地来说,在我们平时爬取网络数据时,通常来说有两种方式。
- 通过 bs4 等库,解析页面的 HTML 代码, 经过解析提取其中的数据,一种所见即所得的爬取方式。
- 通过分析网站的 API 接口调用规则,以对应的规则去请求服务器,直接取得规则的数据,无需二次解析。
了解 API 接口
因为开发技术的发展,在讲究解耦性的情况下,前端(网页结构)与后端(业务处理与数据库)会分开开发,再通过 API 接口来连通数据,这种被称为前后端分离开发。
前后端分离的网页会在返回代码时仅返回基本的 HTML 代码与一段 JavaScript 代码。这段 JavaScript 代码在浏览器端执行时再通过服务器的 API 接口请求数据,将得到的数据填充到网页上,形成我们看到的页面。
还有一种情况是为了保持页面的不变,比如微博页面往下滚动时会持续不断地从服务器获取数据,再追加到页面的微博消息流底下。这些情况都会导致网站服务器存在给前端网页请求的 API 接口,我们只要找到这些接口,便能轻易得到整理好的数据,无需再解析页面源代码。
分析豆瓣电影页面中的 API 接口
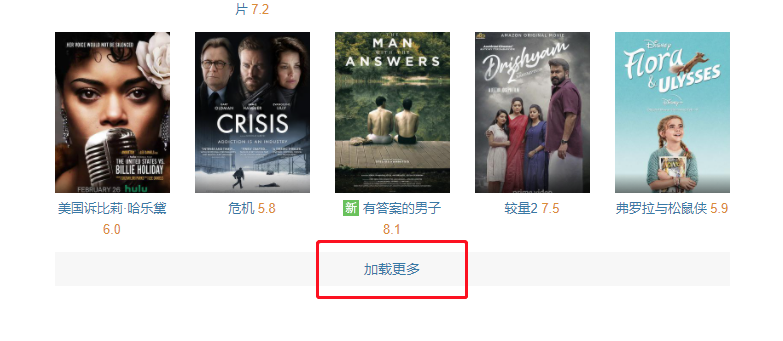
在豆瓣的选电影页面,我们能看到最底部有一个加载更多,说明豆瓣网会在网页运行时通过 API 接口向服务器请求数据。
我们接下来就是要找到这个请求接口 ,并且理解这个接口所需的参数。
打开豆瓣选电影的页面 https://movie.douban.com/explore#!type=movie&tag=热门 。
右键菜单中点击检查,或单击键盘上的 F12。

如无意外,我们会打开开发者工具窗口。

我们点开开发者工具的顶部菜单栏 Network 选项卡,这里会罗列之后所发生的所有网络请求。

让我们在网页中点击一下加载更多。
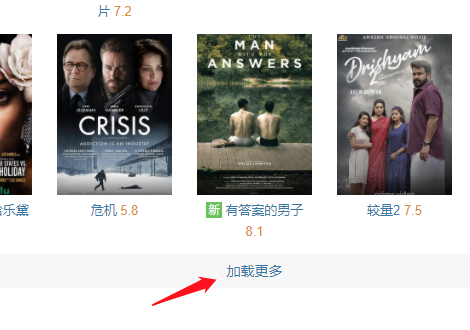
不出意外的,我们看到了很多网络请求,jpg 结尾的是图片的请求,而剩下的那个,就应该是接口的请求了。
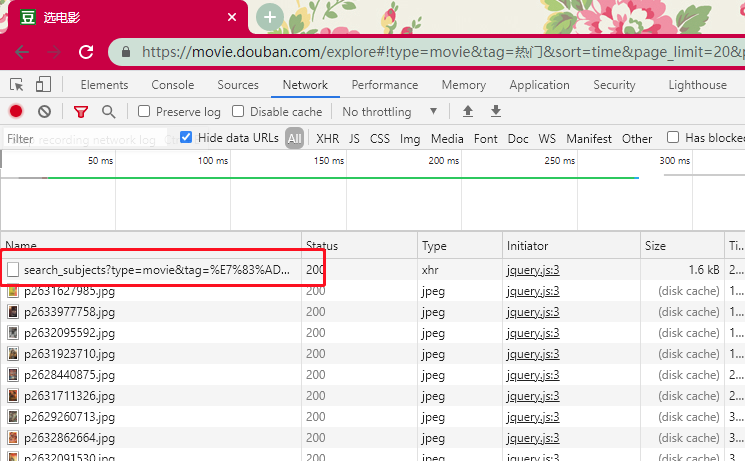
我们也可以点击一下 XHR 过滤一下请求。
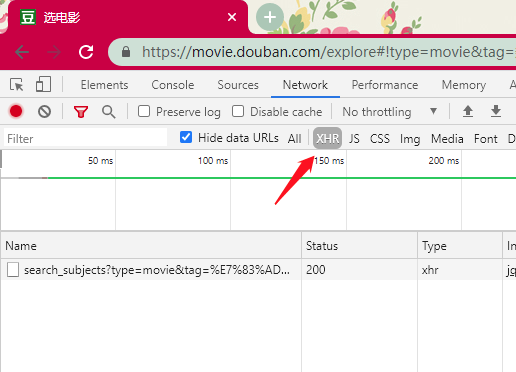
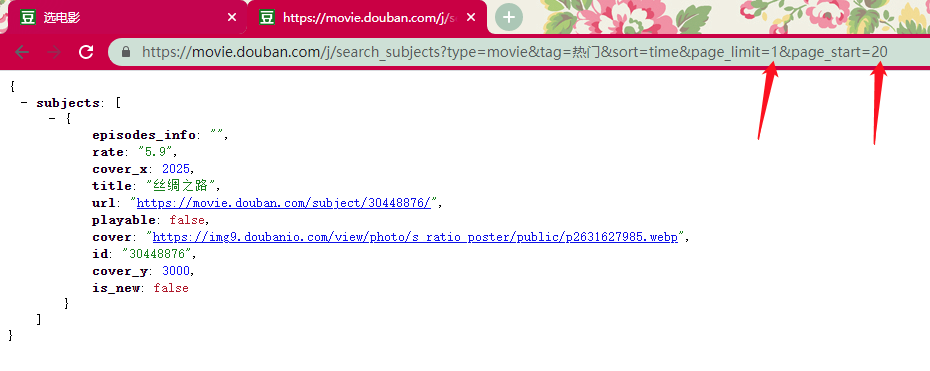
点击这个请求查看它的详细数据,Request URL(https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=20) 便是接口的地址,请求是以 GET 方法发起。
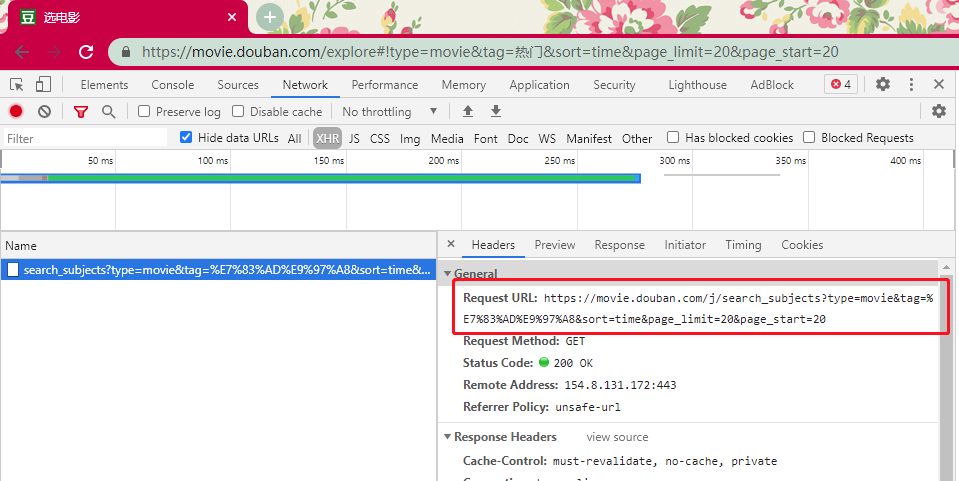
%E7%83%AD%E9%97%A8 是经过 UrlEncode 的中文字符串,为了兼容大部分浏览器,通过会对链接中的特殊字符(包括中文日文等)进行 URL 编码。

我们可以用一些 URL 的解码工具来查看原来的字符。
让我们看看返回的数据,Response 中返回的数据。
不过因为数据是未解码过的,有些不直观,在 Preview 中可以看到更为直观的数据。
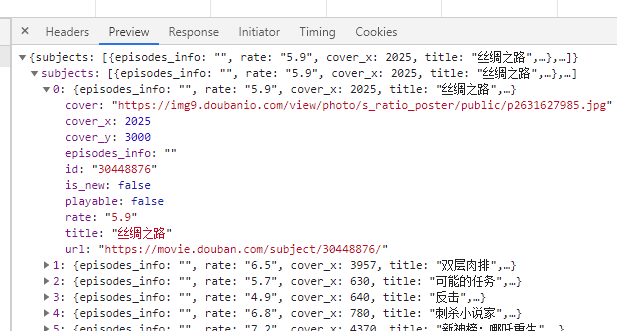
返回的是 json 格式的数据,根据字段的内容推测字段名的含义应该是:
- title:电影名
- url:电影详情页的链接
- cover:电影封面图片地址
- rate:评分
- id:电影在数据库中的唯一标识
- playable:是否可在线播放
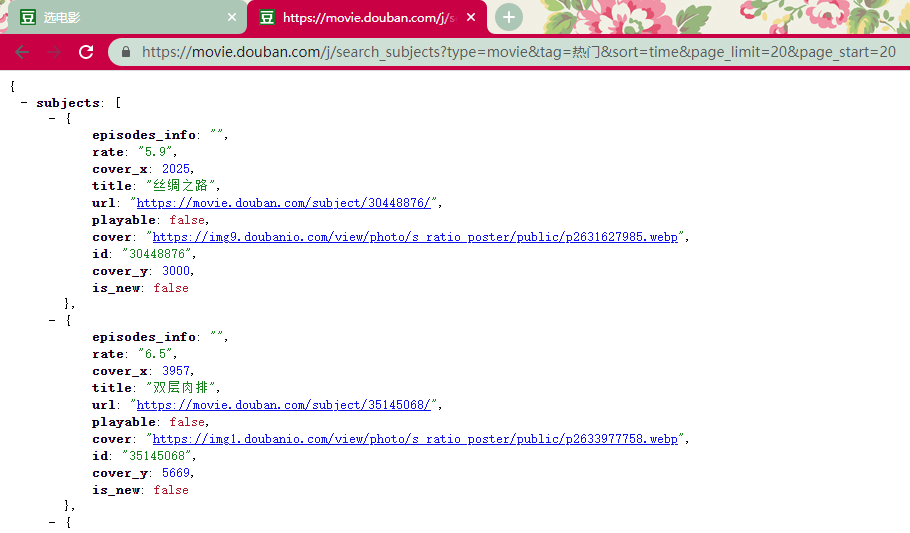
小技巧:由于这个请求是 get 请求, 我们直接复制链接到浏览器地址栏可以测试地址是否可以正确返回数据。
用 reqeusts 请求 API
至此, 我们已经得到了API请求的地址与返回数据的格式。
我们将这个地址用 reqeusts 进行请求,打印其中的数据试试。
import requests
from pprint import pprint
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
# 请求 API 接口
response = requests.get(
'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=20',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
# 因为返回的是 json 格式的数据
# 我们可以直接用 json 方法提取成字典类型
# 小技巧:用 pprint 打印字典数据会展现得更友好
pprint(response.json())
状态码:200
{'subjects': [{'cover': 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2631627985.jpg',
'cover_x': 2025,
'cover_y': 3000,
'episodes_info': '',
'id': '30448876',
'is_new': False,
'playable': False,
'rate': '5.9',
'title': '丝绸之路',
'url': 'https://movie.douban.com/subject/30448876/'},
{'cover': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2633977758.jpg',
'cover_x': 3957,
'cover_y': 5669,
'episodes_info': '',
'id': '35145068',
'is_new': False,
'playable': False,
'rate': '6.5',
'title': '双层肉排',
'url': 'https://movie.douban.com/subject/35145068/'},
......
通过在浏览器地址栏手动调整参数测试,我们可以判断出:
- page_limit:每次请求的数据量
- page_start:从第几条数据开始请求
之后通过调整这两个参数,便可以从豆瓣爬取基本的电影信息。
循环读取数据
我们改造一下代码,从第 1 条数据开始开始,每次读取20条数据。
import requests
from pprint import pprint
# 为了伪装成一个人类
# 我们在请求中带上了虚拟的浏览器信息
agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
page_limit = 20
page_start = 0
data = []
while True:
print(f'爬取 page_start = {page_start} 中')
response = requests.get(
f'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit={page_limit}&page_start={page_start}',
headers={'User-Agent': agent},
)
# 返回的状态码
print('状态码:', response.status_code)
if response.status_code != 200 or len(response.json()['subjects']) == 0:
break
data += response.json()['subjects']
page_start += page_limit
print(f'共抓取了 {len(data)} 条电影数据')
爬取 page_start = 0 中
状态码: 200
爬取 page_start = 20 中
状态码: 200
爬取 page_start = 40 中
状态码: 200
......
爬取 page_start = 380 中
状态码: 200
共抓取了 373 条电影数据
由于我们设定了一个执行条件永远为 True 的循环,不出意外的话代码将一直从豆瓣热门爬取数据直到没有数据。
演示的时候总共爬取了 373 条电影的信息。
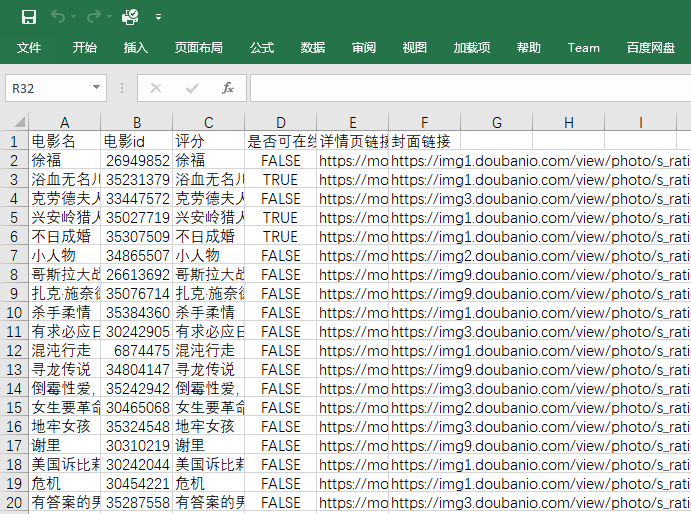
将数据保存到本地
在获取到数据之后,我们要将数据保存下来,不然就是白白浪费服务器资源损人不利己的行为了,会遭天谴,买方便面没调料包。
import csv
with open('热门电影.csv', mode='w', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(
f, delimiter=',', fieldnames=['电影名', '电影id', '评分', '是否可在线播放', '详情页链接', '封面链接']
)
writer.writeheader()
for row in data:
writer.writerow(
{
'电影名': row['title'],
'电影id': row['id'],
'评分': row['title'],
'是否可在线播放': row['playable'],
'详情页链接': row['url'],
'封面链接': row['cover'],
}
)
根据之前分析出来的字段,我们将字段数据一一对应地通过 csv 模块保存到电脑中。最后得到如下图所示的表格文件。
保存封面图片
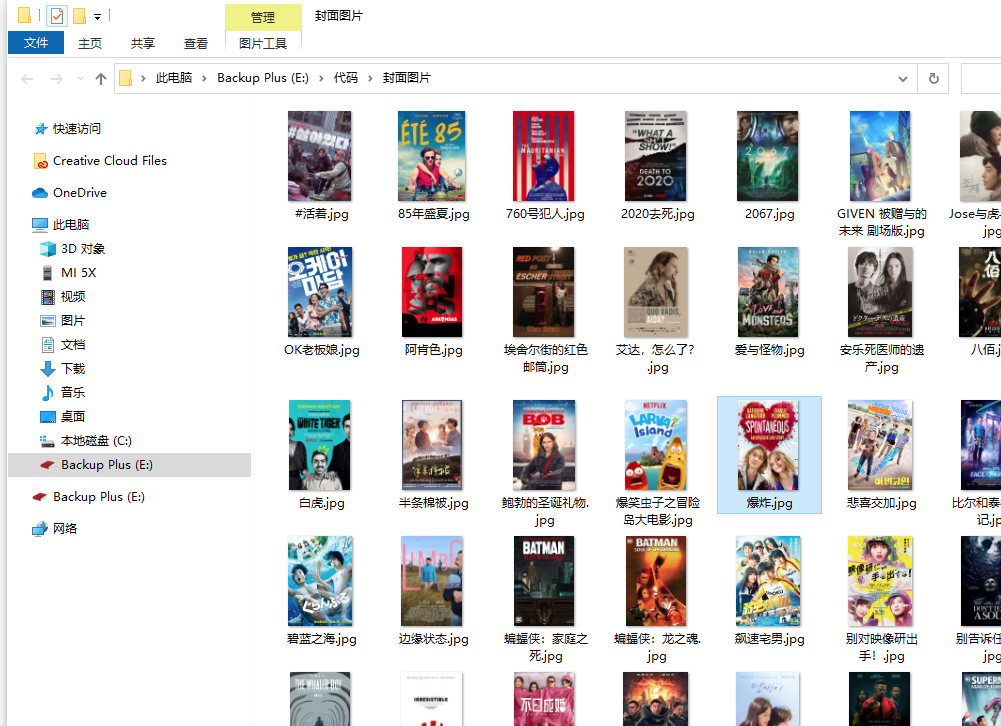
通过 requests.get 方法可以直接获取到图片的二进制数据,用 mode='wb' 的方式打开文件,将其写入硬盘便可以了。
path = '封面图片'
# 判断目录是否存在,不存在则创建
if not os.path.exists(path):
os.makedirs(path)
for row in data:
print('保存{title}的封面中......'.format(title=row['title']))
reponse = requests.get(row['cover'])
# 注意这个打开文件的 mode 为 wb
# w 代表 write 写入
# b 代表 binary 二进制
with open(os.path.join(path, row['title'] + '.jpg'), mode='wb') as f:
f.write(reponse.content)
白杨
2021-05-27
充电宝
2021-11-01